A responsive user interface is a critical aspect of a good user experience, and maintaining responsiveness with increasingly complex applications, with growing data can be very challenging. In this post, I want to look at how to follow the practice of using two distinct UI update phases to achieve optimal performance.
Several months ago I started a new position with Doctor Evidence, and one of our primary challenges is dealing with very large sets of clinical data and providing a responsive UI. This has given me some great opportunities and experience with working on performance with complex UI requirements. I have also been able to build out a library, Alkali, that facilitates this approach.
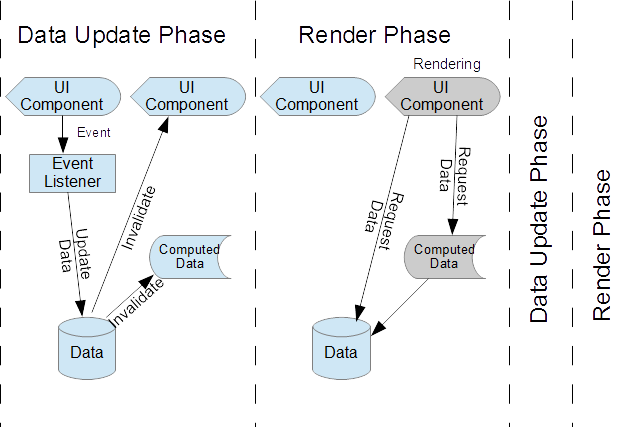
Two phase UI updates basically means that we have one phase that is event-triggered and focused on updating the canonical state of our application, and determining which dependent UI dependencies as invalid, and in need of rerendering. We then have a second phase that is focused on rerendering any UI elements that have been marked as invalid, and computing any derived values in the process.
State Update Phase
The state update phase is a response to application events. This may be triggered by user interaction like clicks, incoming data from a server, or any other type of event. In response to this, the primary concern, as the name suggests, is to update the canonical state of the application. This state may exist at various levels, it could be persisted data models that are synchronized and connected to a server, or it could be higher level “view-models” that are often more explicitly called out in MVVM design and may reflect more transient state. However, the important concept is that we focus on only updating “canonical” state, that is, state information that is not derived from other sources. Derived data should generally not be directly updated at this stage.
The other action that should take place during the state update phase is to invalidate any components that are dependent on the state that is updated. Naturally, the state or data model components should not be responsible for knowledge of which and how to update downstream components, but rather should allow for dependent components to able to register for when a state update has occurred so they can self-invalidate. But the key goal of the invalidation part of the state update phase is to not actually re-render anything immediately, but simply mark what needs to be rendering for the next phase.
This purpose of this approach is that complicated or repetitive state changes will never trigger excessive rendering updates. During state updates, downstream dependent components can be marked as invalid over and over and it will still only need a single rendering in the next phase.
The invalidation should also trigger or queue the rendering actions for the next phase. Fortunately, browsers provide the perfect API for doing exactly this. All rendering should be queued using requestAnimationFrame. This API is already optimized to perform the rendering at the right time, right before the browser lays out and paints, and deferred when necessary to avoid excessive render frequency in the case of rapid events. Fortuneately, much of the complexity of the right timing for rendering is handled by the browser with this API. We just need to make sure our components only queue a single rendering in response to invalidation (multiple invalidations in one phase shouldn’t queue up multiple renderings).
Rendering Phase
The next phase is the rendering phase. At this point, there should be a set of rendering actions that have been queued. If you have used requestAnimationFrame, this phase will be initiated by the browser calling the registered callbacks. As visual components render themselves, they retrieve data from data models, or data model derivatives that are computed. It is at this point that any computed or derived data, that had been invalidated by the previous phase, should now be calculated. This can be performed lazily, in response to requests from the UI components. On-demand computations can avoid any unnecessary calculations, if any computed data is no longer needed.
The key focus in this phase is that we are rendering everything has been invalidated, and computing any data along the way. We must ensure that this phase avoids any updates to canonical data sources during this phase. By separating these phases and avoiding any state updates during rendering, we can eliminate any echo or bouncing of state updates that can slow a UI down or create difficult to debug infinite loops. Batching DOM updates into a single event turn is also an important optimization for avoiding unnecessary changes browser level layout and repaint.
In fact, this two phase system is actually very similar to the way browsers themselves work. Browsers process events, allowing JavaScript to update the DOM model, which is effectively the browser’s data model, and then once the JS phase (state updating) is complete, it enters into its own rendering phase where, based on changed DOM nodes, any relayout or repainting is performed. This allows a browser to function very efficiently for a wide variety of web applications.
An additional optimization is to check that invalidated UI components are actually visible before rerendering them. If a UI component with changed dependent values is not visible, we can simply mark it as needing to be rerendered, and wait until if and when it is visible to do rendering. This can also avoid unnecessary rendering updates.
Alkali
This approach is generally applicable, and can be used with various libaries and applications. However, I have been building, and using a reactive package, alkali, which is specifically designed to facilitate this efficient two phase model. In alkali, there is an API for a Variable that can hold state information, and dependent variables can be registered with it. One can easily map one or multiple variable to another, and alkali creates the dependency links. When a source variable is updated, the downstream dependent variables and components are then automatically invalidated. Alkali handles the invalidation aspect of state updates, as part of its reactive capabilities.
Alkali also includes an Updater class. This is a class that can be used by UI endpoints or components that are dependent on these variables (whether they are canonical or computed). An Updater is simply given a variable, element, and code to perform a rendering when necessary. The Updater will register itself has a dependency of the given variable, and then will be invalidated if any upstream changes are made, and queue its re-rendering via requestAnimationFrame. The rendering code will then be called, as needed, in the proper rendering phase, at the right time.
With alkali, computed variables are also lazy. They will only be computed as needed, on-demand by downstream UI Updaters. They are also cached, so they are only computed one time, to avoid any unnecessary repetition of computations.
As we have tackled large scale data models in a complex UI, the two phase approach was helped us to manage complex state changes, and provide a fast, responsive efficient UI rendering of our data model as state rapidly changes.

April 7, 2017 at 9:12 pm
You are so cool! I do not suppose I’ve truly read something like that before.
So great to find another person with a few unique thoughts on this
issue. Seriously.. many thanks for starting this up.
This web site is something that is required on the web,
someone with some originality!